Contents
A bug report
MathWorks recently received a bug report involving the matrix
X = [ 63245986, 102334155
102334155, 165580141]
X =
63245986 102334155
102334155 165580141
The report claimed that MATLAB computed an inaccurate result for the determinant of X.
format long
detX = det(X)
detX = 1.524897739291191
The familiar high school formula gives a significantly different result.
detX = X(1,1)*X(2,2) - X(1,2)*X(2,1)
detX =
2
While checking out the report, I computed the elementwise ratio of the rows of X and discovered an old friend.
ratio = X(2,:)./X(1,:)
ratio = 1.618033988749895 1.618033988749895
This is $\phi$, the Golden ratio.
phi = (1 + sqrt(5))/2
phi = 1.618033988749895
So, I decided to investigate further.
Powers of a Fibonacci matrix
Let's call the following 2-by-2 matrix the Fibonacci matrix.
$$F = \pmatrix{0 & 1 \cr 1 & 1}$$
Generate the matrix in MATLAB
F = [0 1; 1 1]
F =
0 1
1 1
The elements of powers of $F$ are Fibonacci numbers. Let $f_n$ be the $n$-th Fibanacci number. Then the $n$-th power of $F$ contains three successive $f_n$.
$$F^n = \pmatrix{f_{n-1} & f_n \cr f_n & f_{n+1}}$$
For example
F2 = F*F F3 = F*F2 F4 = F*F3 F5 = F*F4
F2 =
1 1
1 2
F3 =
1 2
2 3
F4 =
2 3
3 5
F5 =
3 5
5 8
The matrix in the bug report is $F^{40}$.
X = F^40
X =
63245986 102334155
102334155 165580141
These matrix powers are computed without any roundoff error. Their elements are "flints", floating point numbers whose values are integers.
Determinants
The determinant of $F$ is clearly $-1$. Hence
$$\mbox{det}(F^n) = (-1)^n$$
So det(F^40) should be 1, not 1.5249, and not 2.
Let's examine the computation of determinants using floating point arithmetic. We expect these to be +1 or -1.
det1 = det(F) det2 = det(F^2) det3 = det(F^3)
det1 =
-1
det2 =
1
det3 =
-1
So far, so good. However,
det40 = det(F^40)
det40 = 1.524897739291191
This has barely one digit of accuracy.
What happened?
It is instructive to look at the accuracy of all the determinants.
d = zeros(40,1); for n = 1:40 d(n) = det(F^n); end format long d
d = -1.000000000000000 1.000000000000000 -1.000000000000000 0.999999999999999 -0.999999999999996 1.000000000000000 -0.999999999999996 0.999999999999996 -1.000000000000057 0.999999999999872 -0.999999999999943 0.999999999997726 -0.999999999998209 1.000000000000227 -1.000000000029786 1.000000000138243 -0.999999999990905 1.000000000261935 -1.000000000591172 0.999999999999091 -0.999999996060069 1.000000003768946 -0.999999926301825 0.999999793712050 -1.000000685962732 0.999998350307578 -0.999995890248101 0.999983831774443 -0.999970503151417 1.000005397945643 -0.999914042185992 0.999138860497624 -0.997885793447495 0.998510751873255 -0.996874589473009 0.973348170518875 -0.989943694323301 0.873688660562038 -0.471219316124916 1.524897739291191
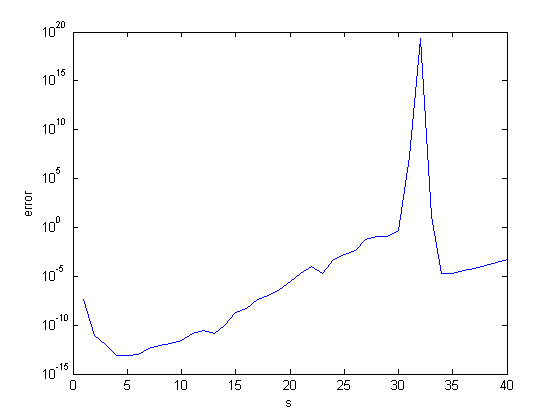
We see that the accuracy deteriorates as n increases. In fact, the number of correct digits is roughly a linear function of n, reaching zero around n = 40.
A log plot of the error
semilogy(abs(abs(d)-1),'.') set(gca,'ydir','rev') title('error in det(F^n)') xlabel('n') ylabel('error') axis([0 41 eps 1])

Computing determinants
MATLAB computes determinants as the product of the diagonal elements of the triangular factors resulting from Gaussian elimination.
Let's look at $F^{12}$.
format long e F12 = F^12 [L,U] = lu(F12)
F12 =
89 144
144 233
L =
6.180555555555555e-01 1.000000000000000e+00
1.000000000000000e+00 0
U =
1.440000000000000e+02 2.330000000000000e+02
0 -6.944444444428655e-03
Since $det(L) = -1$,
det(L)
ans =
-1
we have
det12 = -prod(diag(U))
det12 =
9.999999999977263e-01
We can see that, for $F^{12}$, the crucial element U(2,2) has lost about 5 significant digits in the elimination and that this is reflected in the accuracy of the determinant.
How about $F^{40}$?
[L,U] = lu(F^40) det40 = -prod(diag(U))
L =
6.180339887498949e-01 1.000000000000000e+00
1.000000000000000e+00 0
U =
1.023341550000000e+08 1.655801410000000e+08
0 -1.490116119384766e-08
det40 =
1.524897739291191e+00
The troubling value of 1.5249 from the bug report is a direct result of the subtractive cancellation involved in computing U(2,2). In order for the computed determinant to be 1, the value of U(2,2) should have been
U22 = -1/U(1,1)
U22 =
-9.771908508943080e-09
Compare U22 with U(2,2). The value of U(2,2) resulting from elimination has lost almost all its accuracy.
This prompts us to check the condition of $F^{40}$.
cond40 = cond(F^40)
cond40 = Inf
Well, that's not much help. Something is going wrong in the computation of cond(F^40).
Golden Ratio
There is an intimate relationship between Fibonacci numbers and the Golden Ratio. The eigenvalues of $F$ are $\phi$ and its negative reciprocal.
$$\phi = (1+\sqrt{5})/2$$
$$\bar{\phi} = (1-\sqrt{5})/2$$
format long
phibar = (1-sqrt(5))/2
phi = (1+sqrt(5))/2
eigF = eig(F)
phibar = -0.618033988749895 phi = 1.618033988749895 eigF = -0.618033988749895 1.618033988749895
Because powers of $\phi$ dominate powers of $\bar{\phi}$, it is possible to generate $F^n$ by rounding a scaled matrix of powers of $\phi$ to the nearest integers.
$$F^n = \mbox{round}\left(\pmatrix{\phi^{n-1} & \phi^n \cr \phi^n & \phi^{n+1}}/\sqrt{5}\right)$$
n = 40 F40 = round( [phi^(n-1) phi^n; phi^n phi^(n+1)]/sqrt(5) )
n =
40
F40 =
63245986 102334155
102334155 165580141
Before rounding, the matrix of powers of $\phi$ is clearly singular, so the rounded matrix $F^n$ must be regarded as "close to singular", even though its determinant is $+1$. This is yet another example of the fact that the size of the determinant cannot be a reliable indication of nearness to singularity.
Condition
The condition number of $F$ is the ratio of its singular values, and because $F$ is symmetric, its singular values are the absolute value of its eigenvalues. So
$$\mbox{cond}(F) = \phi/|\bar{\phi}| = \phi^2 = 1+\phi$$
condF = 1+phi
condF = 2.618033988749895
This agrees with
condF = cond(F)
condF = 2.618033988749895
With the help of the Symbolic Toolbox, we can get an exact expression for $\mbox{cond}(F^{40}) = \mbox{cond}(F)^{40}$
Phi = sym('(1+sqrt(5))/2');
cond40 = expand((1+Phi)^40)
cond40 = (23416728348467685*5^(1/2))/2 + 52361396397820127/2
The numerical value is
cond40 = double(cond40)
cond40 =
5.236139639782013e+16
This is better than the Inf we obtain from cond(F^40). Note that it is more than an order of magnitude larger than 1/eps.
Backward error
J. H. Wilkinson showed us that the L and U factors computing by Gaussian elimination are the exact factors of some matrix within roundoff error of the given matrix. With hindsight and the Symbolic Toolbox, we can find that matrix.
digits(25) X = vpa(L)*vpa(U)
X = [ 63245986.00000000118877885, 102334154.9999999967942319] [ 102334155.0, 165580141.0]
Our computed L and U are the actual triangular decomposition of this extended precision matrix. And the determinant of this X is the shaky value that prompted this investigation.
det(X)
ans = 1.524897739291191101074219
The double precision matrix closest to X is precisely $F^{40}$.
double(X)
ans =
63245986 102334155
102334155 165580141
Retrospective backward error analysis confirms Wilkinson's theory in this example.
The high school formula
The familiar formula for 2-by-2 determinants
$$\mbox{det}(X) = x_{1,1} x_{2,2} - x_{1,2} x_{2,1}$$
gives +1 or -1 with no roundoff error for all $X = F^n$ with $n < 40$. It fails completely for $n > 40$. The behavior for exactly $n = 40$ is interesting. Set the output format to
format bank
This format allows us to see all the digits generated when converting binary floating point numbers to decimal for printing. Again, let
X = F^40
X = 63245986.00 102334155.00 102334155.00 165580141.00
Look at the last digits of these two products.
p1 = X(1,1)*X(2,2) p2 = X(2,1)*X(1,2)
p1 = 10472279279564026.00 p2 = 10472279279564024.00
The 6 at the end of p1 is correct because X(1,1) ends in a 6 and X(2,2) ends in a 1. But the 4 at the end of p2 is incorrect. It should be a 5 because both X(2,1) and X(1,2) end in 5. However, the spacing between floating point numbers of this magnitude is
format short
delta = eps(p2)
delta =
2
So near p2 only even flints can be represented. In fact, p1 is the next floating point number after p2. The true product of X(2,1) and X(1,2) falls halfway between p1 and p2 and must be rounded to one or the other. The familiar formula cannot possibly produce the correct result.
Historical irony
For many years, the det function in MATLAB would apply the round function to the computed value if all the matrix entries were integers. So, these old versions would have returned exactly +1 or -1 for det(F^n) with n < 40. But they would round det(F^40) to 2. This kind of behavior was the reason we got rid of the rounding.
eig and svd
Let's try to compute eigenvalues and singular values of $F^{40}$.
format long e eig(F^40) svd(F^40)
ans =
0
228826127
ans =
2.288261270000000e+08
0
Unfortunately, the small eigenvalue and small singular value are completely lost. We know that the small value should be
phibar^40
ans =
4.370130339181083e-09
But this is smaller than roundoff error in the large value
eps(phi^40)
ans =
2.980232238769531e-08
Log plots of the accuracy loss in the computed small eigenvalue and the small singular value are similar to our plot for the determinant. I'm not sure how LAPACK computes eigenvalues and singular values of 2-by-2 matrices. Perhaps that can be the subject of a future blog.
Get
the MATLAB code
Published with MATLAB® 7.14